Peeking Inside Apple's Private Cloud Compute
An unprecedented look into Apple Intelligence's internal server tools and security features

Cover Illustration by onigiriice
———————————————————————————————————————The article contains partial content similar to Matteyeux’s article on the PCC VRE, for more observations about the firmware and its debuggability see the article here
During the development of the iPhone 5s, Apple wanted to do biometrics login with fingerprint scanners but needed a way to store them securely. They have bought the provider of the hardware that will eventually be Touch ID, but needed a way to securely store these biometrics data. If people were gonna give their fingerprint data, they needed to be convinced that it would be safe, unless they want a PR nightmare.
Thus they created the Secure Enclave Processor (SEP), which was built around a dedicated ARMv7a "Kingfisher" core, completely separate from the main application processor (it was not ARM TrustZone, contrary to some accounts). The SEP's isolation ensures that even EL3 (highest privilege level) on the main processor cannot access the Secure Enclave.
Overtime, the responsibility of the Secure Enclave grew to storing banking credentials for Apple Pay, deployment of secure memory regions for trusted execution, secure booting, encryption acceleration, and many more. Today, storing sensitive data feels like second nature, and we trust its security.
With the advent of Generative AI, companies have been rushing to implement LLMs and Image Generation technologies with little to no concern for privacy. Apple is suddenly thrusted into the same dilemma they faced in 2013, as a Pew Research Center survey said that 70% of people say they have little to no trust in companies to make responsible decisions about how they use AI in their products and 81% say the information companies collect will be used in ways that people are not comfortable with.
Early Leaps, Later Bottlenecks
Apple has pride itself on using less memory compared to its competitors, due to its investments in effective memory management for the Darwin kernel which uses Automatic Reference Counting (ARC) as opposed to Android’s use of regular Garbage Collection.

ARC works by having the compiler manually add commands to allocate and release objects (memory) exactly when needed / done. There is overhead with this allocation/deallocation process. However, you end up only having to allocate exactly what you need and the deallocation process occurs in a very predictable manner so as not to interrupt the performance of other processes. GC on the other hand uses an asynchronous process to randomly go through cycles to check and see which memory can be deallocated

This is why iPhones for years have been comfortable with 6 GB of RAM, while flagship Android devices have hit 16 GB even 24 GB of RAM. But this came to bite them when they want to start doing on-device AI inference, which are notoriously memory hungry. Despite efforts like OpenELM, Apple still cannot escape the need to run models in the cloud.
While hardware advances, its likely that advances within LLMs and ImageGen technologies will surpass what is ever capable to be run within mobile battery-powered devices. Seperating data from ML models is hard, because ML models memorize data encoded in their weights as part of training. So there are several ways currently being pursued to do this task, such as :
Machine Unlearning, which is a scheme to remove data from a model. Unfortunately, further proof has shown it to be impossible to formally prove by just querying a model
Secure Multi-Party Computation (SMC), which enables multiple parties to jointly do inference with private data without revealing the actual data to each other through cryptographic protocols, but this requires significant computational overhead
Homomorphic Encryption (HE), which is a method to do complex mathematical operations (including inference) on encrypted data without compromising the encryption. This field has received alot of attention, with scalable solutions like the Brakerski-Fan-Vercauteren Scheme being used by Apple on some smaller ML workloads
Confidential Computing, which is the isolation of data and workloads within a protected central processing unit (CPU) while it is being processed, this is the solution favored by giants like Google and Apple, and which will be the focus of today’s article
Private Cloud Compute
Private Compute Compute (PCC) was created to solve this very issue, a way to run stateless inference in the cloud. This means that while your data goes to the cloud, the data and the model itself won’t accessible and used for further AI training.
Stated by the website itself, PCC has a few key design goals :
Stateless computation: Use personal data only for the immediate task, then delete it completely. No storing or saving allowed
Enforceable guarantees: All parts of the system must be verifiablee to ensure they're following the rules
No special access: Even system administrators can't bypass privacy protections
Non-targetability: Attackers shouldn't be able to target specific users - they'd have to try attacking everyone at once
Verifiable transparency: Outside experts must be able to check that the system actually does what we say it does
This article will attempt to dive more into the security and hardening attempts of CloudOS, but more indepth research will probably be done by people way more talented than i am. I see myself more as a tourist, than a tour guide, for this topic.
To do so, we need to setup the PCC Virtual Research Environment (VRE), which is a part of the macOS 15.1 Developer Preview. The installation process is nearly identical, in that you will need to allow your Mac to run security research VMs, which you can configure within the RecoveryOS terminal by running the following command :
csrutil allow-research-guests enable
The tools is located in /System/Library/SecurityResearch/usr/bin, and requires you to set your shell’s PATH to includes this directory. With iTerm i did this by putting export PATH=$PATH:/System/Library/SecurityResearch/usr/bin at the bottom of my ~/.zshrc file.
After this you’ll need to agree to the license using sudo pccvre license, which grants you research usage to the code and assets within the PCC Virtual Research. Uniquely, this license only grants usage for the VRE for 90-days, which I’m not exactly sure how they’re going to enforce in an open-source project. After agreeing, we can interact fully with the VRE.
We can start by listing the available releases available for download, and then downloading them. When a PCC VRE release has already been downloaded, it does a simple hash check to ensure the integrity of the version that you have on-device. For this instance we are going to use version 1245 which was the latest version at the time of writing, however the example below also shows downloading of a release with a similar hash (1244) and the downloading of a release that is not yet in disk (1242).

Then you can create an instance using pccvre instance create, which will show you the iBoot Serial Console output and the detailed process of the instance.

When the PCCVRE tool is done creating an instance, it will be in an inactive state so to start interacting with it you will need to spin it up. But before doing so, we can interact with the PCC VRE using the darwin-init tool.
➜ ~ pccvre instance configure darwin-init dump -N testing
{
"apply-timeout" : "60min",
"config-security-policy-version" : 8,
"cryptex" : [
{
"url" : "f81cafe498a1081049be16f3c7bc58468d3cb7722aebe365632d99fc0f8a389a.aar",
"variant" : "FM_LANGUAGE_SECURITY_RESEARCH_V1"
},
{
"url" : "2bd63bffc9f8fb5f6827ce5cd4dbbed05f9a7afaad50e01f6c2f71f4fa2796e5.aar",
"variant" : "PrivateCloud Support"
},
{
"url" : "74301a8be3c61debc1377a80b7eeebfbab36639176a5192768ebfe4ccc368a37.aar",
"variant" : "Debug Shell for Private Cloud Security Research VM"
}
],
"log" : {
"system-log-privacy-level" : "Public",
"system-logging-enabled" : false
},
"preferences" : [
{
"application_id" : "com.apple.cloudos.cloudOSInfo",
"key" : "cloudOSBuildVersion",
"value" : "3B5621j.1"
},
{
"application_id" : "com.apple.cloudos.cloudboardd",
"key" : "GRPC",
"value" : {
"ListeningIP" : "0.0.0.0",
"UseSelfSignedCertificate" : true
}
},
{
"application_id" : "com.apple.cloudos.cloudOSInfo",
"key" : "serverOSReleaseType",
"value" : "Darwin Cloud Customer Install"
},
{
"application_id" : "com.apple.cloudos.cloudOSInfo",
"key" : "cloudOSReleaseType",
"value" : "Private cloudOS Customer"
}
],
"result" : {
"failureAction" : "exit"
},
"secure-config" : {
"com.apple.logging.crashRedactionEnabled" : true,
"com.apple.logging.logFilteringEnforced" : true,
"com.apple.logging.metricsFilteringEnforced" : true,
"com.apple.logging.policyPath" : "/private/var/PrivateCloudSupport/opt/audit-lists/customer/",
"com.apple.pcc.research.disableAppleInfrastrucutureEnforcement" : true,
"com.apple.tie.allowClientToOverrideConstraints" : false,
"com.apple.tie.allowClientToOverridePromptTemplate" : false,
"com.apple.tie.allowNonProdExceptionOptions" : false
},
"ssh" : true,
"SSH_DISABLED-config-security-policy" : "customer",
"user" : {
"gid" : 0,
"name" : "root",
"ssh_authorized_key" : "ssh-rsa AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA,
"uid" : 0
},
"userspace-reboot" : "rem"
}
In the documentation, Apple says that the role of darwin-init is similar to Canonical’s cloud-init. Each PCC instance starts from a clean state with no configuration and only the base operating system, then darwin-init is responsible to load in additional required code and configurations from the server’s Baseboard Management Controller (BMC, or similar to lights-out chip solutions like HPE iLO or DELL iDRAC).
Configuration security is managed through the config-security-policy key, which darwin-init uses to enforce environment-specific constraints on allowable configuration options. This mechanism enables development flexibility while maintaining strict security controls in production environments.
The configuration policy state undergoes ratcheting into the Configuration Seal Register, making it available for verification through attestations by user devices. To maintain compatibility and simplify verification between client devices and nodes, the Configuration Seal Register contains only the policy state and specifically selected keys, rather than the complete darwin-init configuration. Within PCC's threat model, this configuration data is treated as attacker-controlled, with darwin-init permitting only configuration options that cannot compromise the system's security or privacy properties, with the safe configuration listed here.
The darwin-init configuration uses a JSON-like format, with several different things we can customize :
Basic Configuration Parameters:
apply-timeoutmaximum time allowed for applying the configurationconfig-security-policy-versionversion of the security policy being used
cryptexto install on the node, here we can see that we have several cryptexes such asFM_LANGUAGE_SECURITY_RESEARCH_V1which is the miniaturized basic LLM model used in the PCC VREPrivateCloudSupportwhich contains Apple’s ML stack and support several other componentsDebug Shell for Private Cloud Security Research VMwhich is a custom cryptex added as part of the VRE for gaining a shell inside of the PCC node, under normal circumstances this isn’t here
logwhich is currently set to disabled and set to public privacy level, by default the PCC does not store application-level logspreferencesContains several important system configurations:cloudOSBuildVersion
3B5621j.1GRPC configuration for
cloudboarddListening on all interfaces (0.0.0.0)
Using self-signed certificates
Server type
Darwin Cloud Customer InstallCloud type
Private cloudOS Customer
secure-configwhich contains various security-related settingsCrash redaction is enabled
Log and metrics filtering are enforced
Custom policy path for auditing
Certain infrastructure enforcement is disabled
TIE restrictions are in place
userthat sets SSH with root accessuserspace-rebootis set to "rem" (Restricted Execution Mode)Failure action is set to "exit"
Aside for the Debug Shell for Private Cloud Security Research VM cryptex, all of these settings are vanilla and should reflect what is being run in production systems at Apple PCC nodes. But these parameters are customizable in the PCC VRE, including features like downgrading certain security protection measures and enabling the collection of logs through the research variant. The VRE Interaction Manual also list ways to gather security telemetry and observability metrics for the PCC through a special configuration for the PCC VRE instance that is editable via the darwin-init tool.
When you’re done setting up your instance build, you can start the instance using the pccvre instance start command.
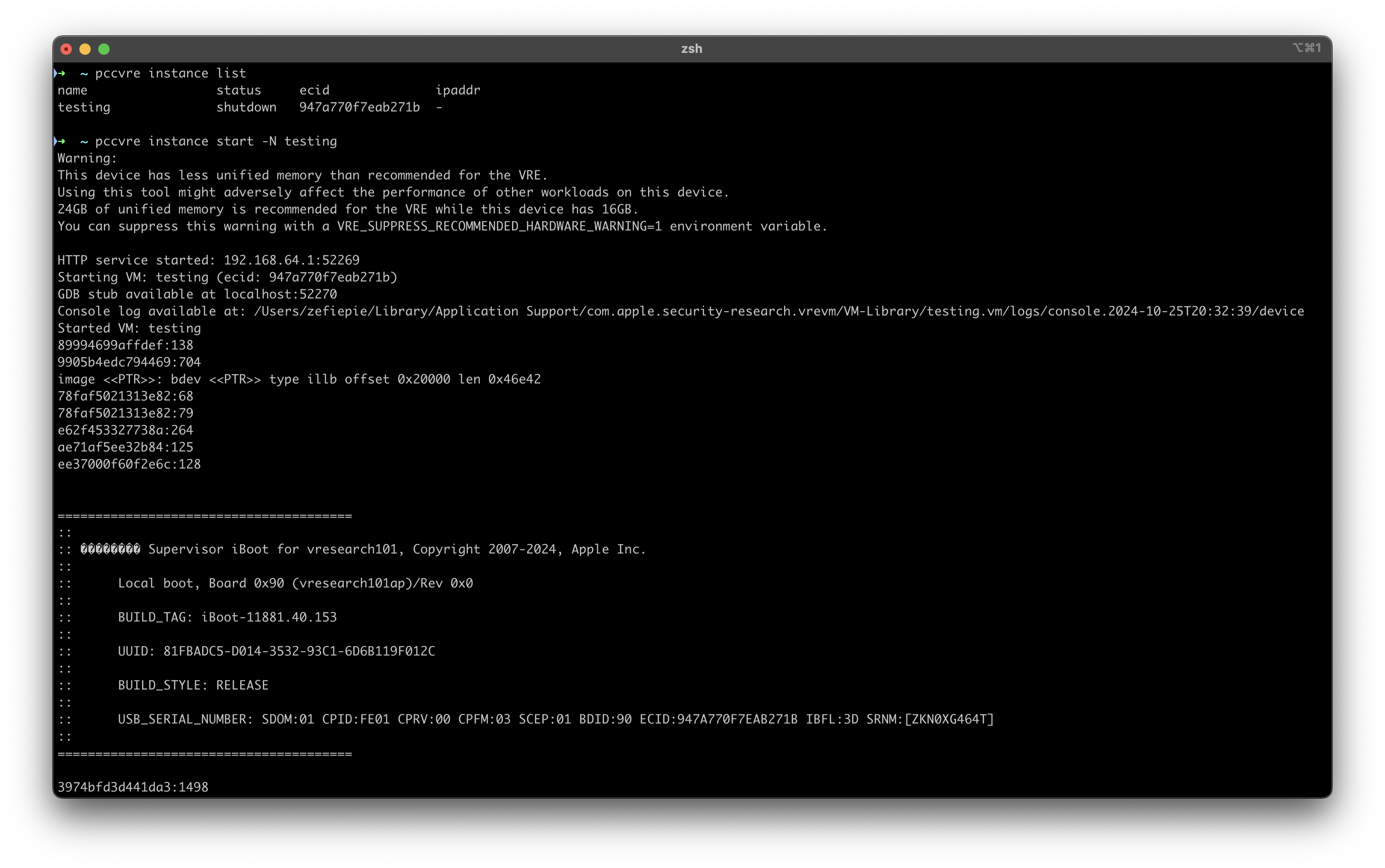

At a high level, the initial stage begins when Boot ROM validates the Image4 boot manifest, known as the APTicket. The APTicket implements cryptographic device personalization through SoC-specific binding using hardware identifiers and TSS-managed rotating anti-replay values. The manifest follows Apple's ASN.1-based Image4 specification, with measurements signed by Apple's Root CA and verified against the public key embedded in Boot ROM.
The Boot ROM's validation sequence performs cryptographic measurements of both iBoot and SEP firmware components through secure hash computations. These measurements must correspond exactly to the signed values in the APTicket manifest. The verification process encompasses ASN.1 structure validation, Root CA signature chain verification, and hardware-specific personalization validation including device identifiers (CPID, ECID) and anti-replay nonce verification.
The manifest validation enforces hardware-binding through cryptographic personalization where device-specific variables (UID, CPID, anti-replay nonces) are incorporated into the signature verification process. This binding ensures APTickets are non-transferable between devices and prevents replay attacks through the TSS-managed rotating values.
Upon successful verification, Boot ROM locks the measurements into two hardware registers:
SEAL_DATA_Afor the AP chain measurementsSEAL_DATAfor SEP measurements
These registers are write-once, creating an immutable record of the verified boot state that becomes integral to the device's attestation system. Only after this verification does the Boot ROM transfer execution control to iBoot. The SEAL register values, combined with other hardware-derived keys and measurements, form the basis for subsequent attestation operations through the Platform Key Accelerator (PKA), enabling remote verification of the device's secure boot state.
iBoot is Apple's proprietary bootloader. This particular readout appears to be from a specialized research or development unit, as indicated by the identifier "vresearch101" in its name. The presence of "Supervisor" in the header suggests this might be running in a privileged or administrative mode.
The boot process shown here is occurring locally on Board 0x90, which is referenced both in the board identification line and in the USB serial number details. The system appears to be running a release build of iBoot version 11881.40.153, suggesting this is a stable, production-ready version. Each boot instance is assigned a unique UUID (81FBADC5-D014-3532-93C1-6D6B119F012C), which helps in tracking and identifying specific boot sessions.
The most detailed information comes from the USB serial number line, which contains several critical identifiers about the hardware. The Chip ID (CPID:FE01) identifies the specific model of Apple silicon being used, while the Exclusive Chip ID (ECID:947A770F7EAB271B) provides a unique identifier for this particular chip - similar to a serial number but at the silicon level. The system's security configuration is indicated by various markers including the Secure Domain (SDOM:01), Security Epoch (SCEP:01), and iBoot flags (IBFL:3D).

iBoot then extends the boot chain by performing its own set of verifications. It validates multiple system firmware components against the APTicket, including three critical components: the Secure Page Table Monitor (SPTM), the Trusted Execution Monitor (TXM), and the Kernel Cache. After successful verification, iBoot hands off execution to the SPTM.
The Secure Page Table Monitor (SPTM) begins its initialization sequence with a critical bootstrap phase that establishes the fundamental security architecture of the system. During bootstrap_stage_announce, SPTM performs several crucial setup operations for the Protected Address Page Table (PAPT) ranges.
The initialization starts with sptm_bootstrap_early, which validates critical parameters where it establishes the initial memory map and prepares for the creation of secure page tables. The system then proceeds with bootstrap_alloc_frames, which allocates the initial set of CTRR-protected frames necessary for maintaining the security of the page table hierarchy.
During this early phase, SPTM configures the IOMMU through the processor subsystem initialization. This involves setting up secure DMA remapping tables, configuring Stream IDs (SIDs), and establishing the initial IOMMU translation tables. The system carefully validates each configuration step to ensure the integrity of IO memory operations.
Following SPTM's initial setup, the system proceeds to initialize the Trusted Execution Monitor (TXM). The TXM initialization process begins with the establishment of the secure execution environment and trust verification mechanisms. The system first loads and verifies the Image4 format firmware components, establishing the root of trust through the certificate chain verification process before then initializing its trust cache system, setting up the verification pathways for different trust domains (PDI, DDI, cryptex). The process includes validation of manifest-properties and boot-manifest-hash to ensure the integrity of the boot chain.
The CoreEntitlements framework is initialized during this phase, establishing the infrastructure for runtime entitlement verification. This includes setting up the acceleration contexts and dictionary structures that will be used for efficient entitlement validation during system operation.
As the boot process continues, SPTM establishes the complete memory management infrastructure. The system initializes the page table hierarchy with strict reference counting (rc16) for tracking page table usage. SPTM sets up the PAPT ranges through bootstrap_register_papt_range, establishing protected memory regions that will be crucial for system security.
Before transferring control to the kernel, the system configures the dispatch mechanism that will control transitions between security domains, setting up the state machine transitions and validation requirements. SPTM then establishes the exception handling pathways through sptm_dispatch, ensuring that all security domain crossings will be properly validated and controlled throughout system operation.
The transfer of control to the kernel represents a critical transition in the boot process. SPTM ensures this transition occurs securely by validating the kernel's code signature through TXM's verification pipeline. It then establishes the initial set of page table mappings that the kernel will operate within, and sets up the security monitor hooks that will continue to enforce memory protection policies during runtime operation.
As the system completes initialization and transitions to user space, the security infrastructure established by SPTM and TXM continues to operate. The entitlement validation system enforces access controls and security policies for running applications. The IOMMU continues to enforce DMA security policies for device interactions.
TXM's trust cache system actively validates code signatures for all executable code loaded into the system, while SPTM performing fundamental security operations like page table management and memory protection. The system is designed such that a TXM compromise doesn’t automatically translate to an SPTM bypass due to this privilege separation.

Parallel to this main boot sequence, the SEP (Secure Enclave Processor) undergoes its own independent boot chain that begins simultaneously with the Application Processor (AP) boot sequence with the SEPROM (Secure Enclave Boot ROM) beginning execution from its immutable code laid down during SoC fabrication, forming the hardware root of trust for the SEP.
The initial boot sequence involves SEPROM setting up the MMU to enable virtual memory address translation. During this initialization phase, SEPROM performs critical setup tasks including storing CPU tick counts, configuring stack pointers, setting up exception vectors, and initializing different CPU modes. Communication between SEP and AP occurs through a dedicated mailbox interface, which is the only communication channel between the two processors. This interface operates through mapped IO registers accessible to both processors, with messages limited to 8 bytes following a structured protocol with specific opcodes.
iBoot is responsible for initiating communication with SEPROM through this mailbox interface. iBoot sends the SEP firmware to SEPROM and sets up the TZ0 registers that define protected memory regions. These TZ0 registers are crucial for memory isolation, using both base and end registers that, once locked, prevent AP access to SEP memory regions.
The memory protection mechanism employs three layers: isolation through AMCC (Apple Memory Cache Controller) preventing AP access to TZ0 memory, encryption using AES-256-XEX(XTS) mode with two 32-byte keys, and integrity checking through checksums of encrypted memory.
SEPROM independently verifies the signature of the sepOS firmware against measurements stored in the APTicket (Image4 boot manifest). Upon successful verification, SEPROM locks these measurements into the SEAL_DATA register, similar to how Boot ROM locks AP measurements in SEAL_DATA_A. This locking mechanism is immutable and cannot be altered after manufacturing, ensuring the integrity of the boot chain.
The actual loading of sepOS occurs after successful verification, with SEPROM copying the verified firmware into protected memory regions established by the TZ0 configuration. The memory layout includes dedicated RAM regions for stack and data, along with carefully mapped IO registers and shared memory regions. After loading sepOS, SEPROM sets up bootargs and transfers control to the SEP firmware.
Once sepOS begins execution, it initializes the SEP application environment, setting up crucial security services including the Platform Key Accelerator (PKA) and various cryptographic operations. The SEP maintains its own nonce for DFU/Recovery operations, further isolating its security state from the AP. Throughout this entire process, the memory regions remain protected by the TZ0 configuration established earlier, preventing any unauthorized access from the AP side.
The PCC, as with other Apple hardware, relies heavily on the Secure Enclave Processor (SEP) for boot and code integrity checking. While the PCC in itself its near, Apple’s new open-gate principle for sepOS caught many by surprise.
In iOS 18 Developer Beta 4, Apple announced that the iBoot and sepOS firmware for the PCC is being released in plaintext. This also coincided with the disabling of firmware encryption for iBoot on iOS, macOS, watchOS, tvOS, and visionOS to increase performance overhead.
While not being mentioned in the release, looking in the source code revealed that Apple opened a GDB stub for the SEP.
case .vresearch101:
let sep_config = _VZSEPCoprocessorConfiguration(storageURL: bundle.sepStoragePath)
if let avpsepbooter { // default AVPSEPBooter.vresearch1.bin from VZ framework
sep_config.romBinaryURL = avpsepbooter
}
sep_config.debugStub = _VZGDBDebugStubConfiguration()
config._coprocessors = [sep_config]
pconf._isProductionModeEnabled = (platformFusing == .prod)
Listing all open ports, we can see that there isn’t just one open port relating to Apple, but three. The top one is the kernel GDB stub i’ve mentioned beforehand, and i can’t seem to find anything related to 53705.
➜ ~ lsof -PiTCP -sTCP:LISTEN
pccvre 21915 zefiepie 14u IPv4 0x5c32866ea688829f 0t0 TCP 192.168.64.1:53704 (LISTEN)
com.apple 21923 zefiepie 7u IPv4 0x98c787175eb69f32 0t0 TCP localhost:53705 (LISTEN)
com.apple 21923 zefiepie 9u IPv4 0x65a79314b9e6fe98 0t0 TCP localhost:53706 (LISTEN)
com.apple 21925 zefiepie 3u IPv4 0x65a79314b9e6fe98 0t0 TCP localhost:53706 (LISTEN)

53706 is the GDB stub for the Secure Enclave, we can figure it out by disassembling some of the code in the higher address spaces where we can find that a string that indicates the sepOS boot code that then jumps to the kernel address. This will likely be an interesting avenue to do SEP/iBoot research moving forward.

The final stage of initialization occurs in user space, where the darwin-init task takes control. This task configures the node based on information it receives from the BMC, including determining which cryptexes to load. After loading all required cryptexes, darwin-init initiates the transition into Restricted Execution Mode (REM). This transition is a one-way process that must meet specific conditions: all "before" code must be unloaded from memory, and the Cryptex Manifest Register must be locked. Only after entering REM does the node become available to serve external requests.
Throughout this process, the system employs Software Sealed Registers (SSRs) to maintain a verifiable record of the boot state. Two specific SSRs are crucial: the Cryptex Manifest Register, which contains digests of Image4 manifests from activated cryptexes, and the Configuration Seal Register, which holds digests of critical darwin-init configuration data. These registers operate on a ratcheting mechanism - once updated, their values cannot be rolled back, and their state is included in all attestations generated by the SEP.
After the process completes, this is where the fun starts. We are offered different ways to interact with the PCC :
A HTTP service was started, no idea what this is used for but it returns an
IOError (other) pread(descriptor:pointer:size:offset:): Is a directory (errno: 21)A GDB stub for kernel debugging
A debug shell cryptex that contains a shell (through SSH)
iOS, Now More Lobotomized!
As said before, CloudOS is just a cut down version of iOS, more very stripped down than it already is. Using the debug cryptex we can gain a shell to CloudOS by using SSH to see further for ourselves.

After enabling SSH in the PCC VRE instance, you can simply login to it like usual.

Welcome to cloudOS, something that you quickly discover is how barebones the VM is. There is no help or clear command, nor any sort of package management system like apt or brew. Built-in interpreters, debuggers, and any sort of Just-In-Time compiler functionality were also removed to prevent dynamic code execution.
After diving into /var/ we finally arrive at the meat of the PCC, which contains alot of files crucial for PCC operations.

There are alot of interesting things here, such as DarwinDataCenterSupportImage which contains support packages for system, in addition to being the place to load and store custom cryptexes. There are also several remenant folders from iOS such as mail and backups, which are empty and are unused (as far as i know.
MLModels also caught my eye, which contains ML models used for the PCC, there is a small model called FM_LANGUAGE_SECURITY_RESEARCH_V1 used for testing purposes.

Additionally, as previously mentioned the PCC VRE provides a GDB stub you can use to connect lldb to. The stub supposedly allows for reading/writing within kernel memory, but without the symbols necessary this is still not that useful.

The fact that there is no way i can figure out (atleast currently) to take data out of the vanilla PCC VRE kinda makes me believe that Apple is making good on its promise to not use user data and interactions with Apple Intelligence for inference purposes.
Stateless Inferencing
PCC VRE won’t be the only example of using confidential computing for securing inference workloads, as Google has already published a proof-of-concept implementation using gRPC over HTTPS to connect a Confidential VM containing Gemma 2B.
Rather than requiring a complex setup with a client device, the PCC VRE offers a wrapper to talk to the LLM inside of the PCC.

The wrapper connects to an endpoint provided by the cloudboardd service in the Virtual Runtime Environment (VRE). This is the same endpoint that the PCC Gateway utilizes for connecting to PCC nodes in production environments. The pccvre tool leverages the CloudBoard and TIE application protocols to handle request submission and response display.
The command prints the result of the SEP attestation, then tokens as they are streamed, and finally the fully formed response.

The idea is that once your request gets inferenced within the PCC, sent back to you, and the data is immediately destroyed. User data is designed to never be available to Apple, even to staff with administrative access to the production service or hardware.
The core of the inference operations lies in The Inference Engine (TIE), which handles the logic of executing inference requests that users submit to PCC. Requests are received on the PCC node by CloudBoard, which is responsible for implementing the cryptographic protocol with a user’s device, and are then handed off to TIE for processing. The tie-model-owner process employs the ModelCatalogSE framework to load model weights, adapters, and associated parameters from disk into memory.
ModelCatalogSE maintains an index of model data and metadata, including tokenizers, stop tokens, and prompt templates, which are derived from model and adapter cryptexes on the PCC node. The inference components operate under the orchestration of a single tie-controllerd daemon, which functions as TIE's primary control system, managing inference process recycling, and initiates periodic CIO mesh key rotations. Furthermore, tie-controllerd interfaces with CloudBoard's Runtime configurable properties to retrieve prompt deny lists, which enumerate blocked inputs that could potentially compromise system stability.
When requests arrive at a PCC node, TIE processes them through an ephemeral, per-request tie-cloud-app instance. The system utilizes process pooling to mitigate process spawning runtime overhead, that comprise of pre-instantiated cb_jobhelper and tie-cloud-app pairs maintained in readiness to service requests. Upon CloudBoard's selection of a tie-cloud-app instance for request handling, the application deserializes the incoming Protobuf-encoded request, validates request parameter safety, and tokenizes the string-based prompt using the model cryptex-specified tokenizer.
message InvokeWorkloadRequest {
oneof type {
Setup setup = 1;
Terminate terminate = 2;
Chunk request_chunk = 3;
Parameters parameters = 4;
}
}
message InvokeWorkloadResponse {
oneof type {
SetupAck setup_ack = 1;
Chunk response_chunk = 2;
}
}
TIE executes tokenization within a per-request process to isolate untrusted string input parsing. The implementation of per-request process instances ensures that potential process compromises would not expose other users' request data. The system discards all intermediate request data upon request completion and process termination. After initial request processing, the tie-cloud-app transmits the request to a shared tie-inference process that executes the inference using MetalLM. The request data encompasses the tokenized input, model and adapter identifiers for inference, sampling parameters, and when applicable, the constrained decoding grammar.
To minimize the risk of unexpected user data retention beyond single request lifetimes in the inference host process, the tie-controller periodically terminates and restarts tie-inference which ensures that data processed within previous inference host instances remains inaccessible to potential attacks that might compromise future instances.
Within MLModels/LLM/FM_LANGUAGE_SECURITY_RESEARCH_V1/LLM.Model/4.0.0 sits a 1.8 GB model.mlm file, which is a small machine learning model created in Apple Create ML. Admittedly i was abit disappointed because i thought Apple will lend a peek into the bigger LLM models they supposedly have in the cloud.
The model within the PCC VRE is likely based on Apple’s open source OpenELM-450M simply by seeing the model size, with the model being converted to support Apple’s CreateML Framework. But the PCC is supposed to house bigger models, which are called Apple Foundation Models (AFM) which are dense decoder-only models that build on the Transformer architecture with the following design choices:
A shared input/output embedding matrix to reduce parameter count, and therefore memory usage.
Pre-Normalization with RMSNorm for training stability.
Query/key normalization to improve training stability.
Grouped-query attention (GQA) with 8 key-value heads to reduce the KV-cache memory footprint.
SwiGLU activation for higher efficiency.
RoPE positional embeddings with the base frequency set to 500k for long-context support.
Consistent with Apple’s whole branding on privacy-preservation, the data used for Apple Intelligence is also supposedly open sourced. The AFM pre-training dataset consists of a diverse and high quality data mixture:
Web pages: Crawled using Applebot, respecting publishers’ rights to opt out. The data is filtered to exclude profanity, unsafe material, personally identifiable information (PII), and processed through a pipeline that performs quality filtering, plain-text extraction, and decontamination against 811 common pre-training benchmarks.
Licensed datasets: High-quality data licensed from publishers, providing diverse and long-context data for continued and context-lengthening stages of pre-training. The data is decontaminated in the same way as web pages.
Code: Obtained from license-filtered open-source repositories on GitHub, covering 14 common programming languages. The data is de-duplicated, filtered for PII and quality, and decontaminated in the same fashion as web pages.
Public datasets: High-quality publicly-available datasets with licenses permitting use for training language models. The datasets are filtered to remove PII before being included in the pre-training mixture.
Math: Two categories of high-quality data sourced from the web:
Math Q&A dataset: 3 billion tokens from 20 web domains rich in math content, extracted by identifying relevant tags from HTML pages.
Collection of 14 billion tokens from web pages such as math forums, blogs, tutorials, and seminars. The data is filtered using a specialized pipeline that includes math tag filters, symbol filters, quality filters powered by language models, and domain filters processed by humans.
While there are concerns that the models inside of the PCC can still using user data for training, Apple has said that it does not use private user data or interactions with Apple Intelligence when training its foundational models. If Apple complies to this, then it does mean that they have achieved the capability to do stateless inferencing without resorting to exotic methods mentioned earlier.
Minimal Logging and Telemetry
Every single server-side application will need somesort of logging and telemetry system to ensure the availability and security of the applications being run. But how do you do it inside of a system that is supposed to be a black-box to outsiders and does not collect any data whatsover?
At the core of this is CloudMetrics, which implements the swift-metrics API backend. This system enables software within the PrivateCloudSupport cryptex to log various metric types including counters, gauges, and histograms. The metric collection process follows a structured flow where observations are first provided to the CloudMetrics framework, then transmitted via XPC to the cloudmetricsd daemon where temporal aggregation occurs locally. These aggregated metrics are subsequently exported to Apple's metrics service using the OpenTelemetry Protocol, an industry-standard for observability data transmission.
The system implements strict controls over metric collection through a restrictive allow-list mechanism within CloudMetrics. This framework exercises granular control over metric export frequency and implements filtering based on metric names, allowed dimensions, and valid value ranges. Importantly, these configurations reside within the PrivateCloudSupport cryptex, ensuring they fall under PCC's verifiable transparency guarantees.
For logging capabilities, PCC utilizes the privacy-conscious os_log API, with log export handled by the splunkloggingd daemon. This daemon implements sophisticated filtering rules that operate on a per-log-line basis, scrutinizing both the message sender (identified by the Mach-O image) and the format string. The system maintains a carefully curated allow list of permitted messages, which undergoes rigorous privacy review considering not only the format strings but also the data types of included variables.
The crash reporting system in PCC builds upon existing privacy-preserving infrastructure from macOS and iOS, but implements additional safeguards. It categorizes crash data into intrinsically safe attributes (such as OS version and process IDs) and process state dependent data (like stack traces and register state). The system applies two levels of redaction - partial and full - with strict rate limiting of partially redacted logs to a maximum of three per node per hour, randomly selected from 20% of crashes.
We finally meet again with an old friend, the EndpointSecurity API, which is responsible for monitoring security events in MacOS. PCC nodes capture only a few events, mainly
ES_EVENT_TYPE_NOTIFY_EXEC(for process execution)ES_EVENT_TYPE_NOTIFY_EXIT(for process exit)ES_EVENT_TYPE_NOTIFY_IOKIT_OPEN(activation of certain hardware features)ES_EVENT_TYPE_NOTIFY_OPENSSH_LOGIN(SSH logins)ES_EVENT_TYPE_NOTIFY_OPENSSH_LOGOUT(SSH logouts)NetworkStatistics(Network inbound/outbound connections)
The security event collection system prioritizes metadata capture over process introspection, implementing a privacy-first approach to security monitoring. Event export occurs through the splunkloggingd daemon, utilizing the same robust filtering mechanism that governs log message export. The configuration controlling permitted security events resides within the PrivateCloudSupport cryptex, ensuring transparency and verifiability of the monitoring scope.
All collected security events undergo aggregated analysis by Apple's security teams to identify potential compromise indicators. This analysis occurs within a framework that maintains PCC's core privacy guarantees while enabling effective security monitoring. The system achieves this balance by focusing on event patterns and metadata analysis rather than direct examination of process internals or user data.
The entire observability and security monitoring infrastructure operates within PCC's network security framework, controlled by the denaliSE firewall agent. This agent ensures that all monitoring and metric data transmission occurs only to authorized data center services, operating under mutual TLS authentication with certificates managed by the Secure Enclave Processor. This network-level control provides an additional layer of protection against unauthorized data exfiltration while enabling essential operational monitoring.
Conclusions
From the brief examination of the OS and tooling surrounding the PCC, we can somewhat confidently that Apple is atleast lining itself for a really big lawsuit if it doesn’t play along with its privacy guarantees for Apple Intelligence and other offloaded AI/ML workloads. There is probably much more to discover, which will probably be covered by people that are way more technically proficient than myself.
I think the privacy guarantees around Apple Intelligence and the unprecendented access to the tools that support its secure operations is a big step towards providing a more privacy-preserving AI platform, which has certainly come a long way from Apple’s first inclusion of privacy-preserving technologies like the Secure Enclave. Apple has been working hard in implementing other, more bulletproof, solutions such as Homomorphic Encryption (HE) for ML workloads and a focus towards more on-device inference for sensitive items such as for sensitive content detection.
This doesn’t mean Apple Intelligence is fully secure, as it still relies on API calls to notorious AI firms like OpenAI which has been known to be very data hungry. Fortunately, Apple always asks before your requests are sent to non-Apple entities and these features can be turned off unlike other shoehorned AI systems recently. Apple also has a history in compromising the security of its server infrastructure to comply to national regulations in countries like Mainland China.
The thing is that if your mind is already made up on this technology, and you know who you are, its more likely that you’ve already made up your mind and all of these attempts are unconvincing for you. For you, Apple has also given the option to completely disable Apple Intelligence. Apple also give guidelines on how to set robots.txt parameters to stop your data from being scraped by Applebot (Apple’s web scraper) and how to request to opt-out of training entirely.
The thing i want to underscore is that i do believe the oversimplification and subsequent demonization of AI technologies is dangerous, because its the same technology that’s responsible from everything from helping me remember my vacation with my family from three years ago to the early detection of breast cancer. We should encourage the research and development towards how to integrate these technologies in a better and safer way, not ban them outright.